Ateliers R Trucs et Astuces
Introduction à la manipulation des données sous tidyverse
INRAE UMR EcoSys
1/3/26
| Organisation |
|---|
| Utilisation générale |
Les principales fonctions dplyr |
Graphiques avec ggplot2 et palmerpenguins |
| Et pleins d’exercices ! |
Utilisation générale
Packages nécessaires
tidyversepalmerpenguins
Utilisation générale
Le package dplyr (inclus dans le jeu de packages tidyverse) facilite le traitement et la manipulation de données contenues dans une ou plusieurs tables (dataframe ou de tibble).
Il repose sur syntaxe claire et cohérente, sous formes de verbes.
Ex = la fonction select() sélectionne des colonnes, la fonction filter() filtre les données par colonne.
Ces fonctions peuvent s’utiliser les unes après les autres, en utilisant le symbole “%>%” (pipe en anglais).
Ex : ma_table %>% select(colonne_1) %>% summarize(moyenne = mean(colonne_1))
Utilisation générale
| Les différentes familles de fonction |
|---|
Remodeler ses données avec rename, relocate, spread, gather, et arrange |
Trier ses données select, filter, distinct, slice et sample_n |
Créer de nouvelles variables avec mutate |
Synthétiser ses données avec summarize et group_by |
Recoder ses données avec recode, case_when |
Réaliser des jointures entre tables avec left_join, right_join, inner_join, full_join |
SELECT
Permet de :
- sélectionner des colonnes : ma_table %>% select(colonne_1, colonne_2)
- Supprimer des colonnes : ma_table %>% select(-colonne_1, -colonne_2)
Il est possible de sélectionner les colonnes par leur nom ou par leur numéro de colonne.
Ex: ma_table %>% select(1, 3, 5)
Ex: ma_table %>% select(1:3, 5:7)
SELECT
Présentation des données
| name | height | mass | hair_color | skin_color | eye_color | birth_year | gender | homeworld | species | sex |
|---|---|---|---|---|---|---|---|---|---|---|
| Luke Skywalker | 172 | 77 | blond | fair | blue | 19 | masculine | Tatooine | Human | male |
| C-3PO | 167 | 75 | NA | gold | yellow | 112 | masculine | Tatooine | Droid | none |
SELECT
Sélection de 3 colonnes : name, height, mass
| name | height | mass |
|---|---|---|
| Luke Skywalker | 172 | 77 |
| C-3PO | 167 | 75 |
SELECT
Autre utilité de select : réordonner les colonnes d’une table
| name | species | gender | height | mass | homeworld |
|---|---|---|---|---|---|
| Luke Skywalker | Human | masculine | 172 | 77 | Tatooine |
SELECT
| species | name | height | mass | gender | homeworld |
|---|---|---|---|---|---|
| Human | Luke Skywalker | 172 | 77 | masculine | Tatooine |
RELOCATE
Une autre solution pour réordonner les colonnes : relocate
- Déplacer une colonne ou plusieurs colonnes au début :
ma_table %>% relocate(colonne_4, colonne_5) - Déplacer une colonne après une autre colonne :
ma_table %>% relocate(colonne_4, .after=colonne_1) - Déplacer une colonne avant une autre colonne :
ma_table %>% relocate(colonne_4, .before=colonne_1)
RELOCATE
| name | height | mass | species | gender | homeworld |
|---|---|---|---|---|---|
| Luke Skywalker | 172 | 77 | Human | masculine | Tatooine |
| C-3PO | 167 | 75 | Droid | masculine | Tatooine |
| name | gender | height | mass | species | homeworld |
|---|---|---|---|---|---|
| Luke Skywalker | masculine | 172 | 77 | Human | Tatooine |
| C-3PO | masculine | 167 | 75 | Droid | Tatooine |
RENAME
Permet de renommer les colonnes
ma_table %>% rename(nouveau_nom = ancien_nom)
| nom | taille | poids |
|---|---|---|
| Luke Skywalker | 172 | 77 |
| C-3PO | 167 | 75 |
| R2-D2 | 96 | 32 |
| Darth Vader | 202 | 136 |
| Leia Organa | 150 | 49 |
| Owen Lars | 178 | 120 |
| Beru Whitesun lars | 165 | 75 |
FILTER
Permet de sélectionner des observations selon une ou plusieurs conditions. Seules les observations qui respectent la condition sont conservées (renvoie TRUE).
ma_table %>% filter(colonne_1 > valeur)
ma_table %>% filter(colonne_2 == "texte")
ma_table %>% filter(colonne_3 %in% c(valeur1, valeur2, valeur3))

FILTER
| name | height | mass |
|---|---|---|
| Darth Vader | 202 | 136 |
| Tarfful | 234 | 136 |
| name | height | mass |
|---|---|---|
| Arvel Crynyd | NA | NA |
ARRANGE
Réordonne les lignes d’un tableau selon une ou plusieurs colonnes.
- Par ordre croissant : ma_table %>% arrange(colonne_1)
- Par ordre décroissant : ma_table %>% arrange(desc(colonne_1))
Dans le cas ou plusieurs colonnes doivent être réordonnées, la première colonne prévaut.
ARRANGE
| name | height | mass |
|---|---|---|
| Yoda | 66 | 17 |
| Ratts Tyerel | 79 | 15 |
| name | height | mass |
|---|---|---|
| Yarael Poof | 264 | NA |
| Tarfful | 234 | 136 |
A VOUS DE CODER
A partir du jeu de données “penguins_raw”, créer un nouveau jeu de données répondant aux consignes suivantes :
- Sélectionner les colonnes : “Species”, “Island”, “Flipper Length (mm)”, “Body Mass (g)”, “Sex”
- Renommer les colonnes pour enlever les caractères spéciaux, les espaces et les majuscules
- Enlever les NA des colonnes “flipper_length_mm” et “body_mass_g”
- Ne garder que les îles “Torgersen” et “Dream”
- Réordonner le tableau selon la taille des ailes par ordre décroissant et le poids par ordre croissant
- Déplacer la colonne “sex” pour la mettre après la colonne “island”
MUTATE
Permet de créer de nouvelles colonnes ou de modifier des colonnes existantes.
Il est possible d’utiliser toutes sortes de fonctions à l’intérieur d’une étape mutate
- Calcul simple :
ma_table %>% mutate(new_colonne = colonne_1*100)
ma_table %>% mutate(colonne_1 = colonne_1*100)
- Calculer une somme cumulée :
ma_table %>% mutate(new_colonne = cumsum(colonne_1, na.rm = T))
- Calculer un total :
ma_table %>% mutate(new_colonne = sum(colonne_1, na.rm = T))
- Sommer deux variables :
ma_table %>% mutate(new_colonne = colonne_1 + colonne_2) - Extraire une sous-chaine de caractères:
ma_table %>% mutate(new_colonne = str_sub(colonne_3, 1, 4))
MUTATE
| name | height | mass | imc |
|---|---|---|---|
| Luke Skywalker | 172 | 77 | 26.02758 |
| C-3PO | 167 | 75 | 26.89232 |
| R2-D2 | 96 | 32 | 34.72222 |
| Darth Vader | 202 | 136 | 33.33007 |
| Leia Organa | 150 | 49 | 21.77778 |
| Owen Lars | 178 | 120 | 37.87401 |
| Beru Whitesun lars | 165 | 75 | 27.54821 |
| R5-D4 | 97 | 32 | 34.00999 |
| Biggs Darklighter | 183 | 84 | 25.08286 |
| Obi-Wan Kenobi | 182 | 77 | 23.24598 |
SUMMARISE
Permet de calculer une ou plusieurs statistiques à partir de la table de données.
Cette fonction est souvent utilisée après la fonction group_by pour calculer des statistiques par groupe.
De la même manière que mutate , il est possible de faire appel à un grand nombre de fonctions différentes avec summarise.
ma_table %>% summarize(valeur_agregee = fonction(colonne_1))
| Fonction | Code |
|---|---|
| Moyenne | mean() |
| Médiane | median() |
| Ecart-type | sd() |
| Minimum | min() |
| Maximum | max() |
| Valeur de la première valeur | first() |
| Fonction | Code |
|---|---|
| Valeur de la dernière valeur | last() |
| Nombre de lignes | n() |
| Nombre de valeurs distinctes | n_distinct() |
| Somme | sum() |
| Somme cumulée | cumsum() |
SUMMARISE
| nbre_individu | poids_moyen | poids_mediant | poids_sd |
|---|---|---|---|
| 82 | 97.31186 | 79 | 169.4572 |
GROUP_BY
Permet de définir des groupes dans la table de données pour faire des opérations par groupe.
L’utilisation de group_by() est le plus souvent couplé avec summarise mais également avec mutate et filter.
ma_table %>% group_by(colonne_1) %>% summarize(valeur_agregee = fonction(colonne_2))
ma_table %>% group_by(colonne_1) %>% mutate(new_colonne = fonction(colonne_2))
ma_table %>% group_by(colonne_1) %>% filter(colonne_2 = fonction(colonne_2))
GROUP_BY + SUMMARIZE
| species | nbre_individu | poids_moyen | poids_mediant | poids_sd |
|---|---|---|---|---|
| Human | 35 | 81.26957 | 79.0 | 20.278928 |
| Droid | 5 | 69.75000 | 53.5 | 51.031853 |
| Gungan | 3 | 74.00000 | 74.0 | 11.313709 |
| Kaminoan | 2 | 88.00000 | 88.0 | NA |
| Mirialan | 2 | 53.10000 | 53.1 | 4.384062 |
GROUP_BY + MUTATE
| name | species | mass | nbre_individu | poids_moyen | poids_mediant | poids_sd |
|---|---|---|---|---|---|---|
| Luke Skywalker | Human | 77 | 35 | 81.26957 | 79.0 | 20.27893 |
| C-3PO | Droid | 75 | 5 | 69.75000 | 53.5 | 51.03185 |
| R2-D2 | Droid | 32 | 5 | 69.75000 | 53.5 | 51.03185 |
| Darth Vader | Human | 136 | 35 | 81.26957 | 79.0 | 20.27893 |
GROUP_BY + FILTER
| name | species | mass |
|---|---|---|
| Greedo | Rodian | 74 |
| Jabba Desilijic Tiure | Hutt | 1358 |
| Yoda | Yoda’s species | 17 |
| Bossk | Trandoshan | 113 |
A VOUS DE CODER
A partir du jeu de données “penguins”, créer un nouveau jeu de données répondant aux consignes suivantes :
- Sélectionner les colonnes : “species”, “island”, “flipper_length_mm”, “body_mass_g”, “sex”
- Déplacer la colonne “island” pour la mettre en fin du jeu de données
- Calculer le pourcentage de chaque espèce pour chacune des îles
- Réordonner les observations par île (ordre alphabétique)
- Faire un graphique qui représente ces données (ex : Diagramme en barre)
RECODE
Permet de recoder des valeurs spécifiques dans un data.frame.
ma_table %>% mutate(colonne_1 = recode(colonne_1, "ancienne_valeur = "nouvelle valeur", "ancienne_valeur2"= "nouvelle_valeur2"))
L’utilisation de l’argument .default permet de donner une valeur par défaut aux valeurs non recodées.
``ma_table %>% mutate(colonne_1 = recode(colonne_1, "ancienne_valeur = "nouvelle valeur", .default= valeur_defaut))
Spécificité des NA : pour les remplacer, utiliser replace_na()du package tidyr inclus dans tidyverse
RECODE
[1] "Human" "Droid" "Wookie" "Rodian"
[5] "Hutt" "Yoda's species" "Trandoshan" "Mon Calamari"
[9] "Ewok" "Sullustan" "Neimodian" "Gungan"
[13] "Toydarian" "Dug" "Zabrak" "Twi'lek"
[17] "Aleena" "Vulptereen" "Xexto" "Toong"
[21] "Cerean" "Nautolan" "Tholothian" "Iktotchi"
[25] "Quermian" "Kel Dor" "Chagrian" "Geonosian"
[29] "Mirialan" "Clawdite" "Besalisk" "Kaminoan"
[33] "Skakoan" "Muun" "Togruta" "Kaleesh"
[37] "Pau'an" RECODE
| name | species |
|---|---|
| Ratts Tyerel | Aleena |
| Yoda | Y |
| Wicket Systri Warrick | Ewok |
| R2-D2 | Droid |
| R5-D4 | Droid |
| Sebulba | Dug |
| Padmé Amidala | H |
| Dud Bolt | Vulptereen |
| Wat Tambor | Skakoan |
| Sly Moore | H |
RECODE
| name | species |
|---|---|
| Ratts Tyerel | Autre |
| Yoda | Y |
| Wicket Systri Warrick | Autre |
| R2-D2 | Autre |
| R5-D4 | Autre |
| Sebulba | Autre |
| Padmé Amidala | H |
| Dud Bolt | Autre |
| Wat Tambor | Autre |
| Sly Moore | H |
CASE_WHEN
Permet de réaliser des opérations conditionnelles sur les données.
Elle est souvent utilisée pour créer de nouvelles variables en fonction de conditions spécifiques.
ma_table %>% mutate(new_colonne = case_when(condition1 ~ valeur1, condition2 ~ valeur2, TRUE ~ valeur3))
ma_table %>% mutate(new_colonne = case_when(colonne1 < colonne2 ~ valeur1, condition1 > colonne 3 ~ valeur2, TRUE ~ valeur3))
La condition TRUE ~ valeur est utilisée comme valeur par défaut si aucune des conditions précédentes n’est satisfaite.
CASE_WHEN
people %>%
dplyr::select(name, height) %>%
mutate(categorie = case_when(
height < quantile(height, 0.25, na.rm = T) ~ "petit",
between(height, quantile(height, 0.25, na.rm = T), quantile(height, 0.75, na.rm = T)) ~ "moyen",
height >= quantile(height, 0.75, na.rm = T) ~ "grand",
TRUE ~"indefini")) %>%
slice(1:8)| name | height | categorie |
|---|---|---|
| Luke Skywalker | 172 | moyen |
| C-3PO | 167 | moyen |
| R2-D2 | 96 | petit |
| Darth Vader | 202 | grand |
| Leia Organa | 150 | petit |
| Owen Lars | 178 | moyen |
| Beru Whitesun lars | 165 | petit |
| R5-D4 | 97 | petit |
DISTINCT
Permet d’extraire les lignes uniques d’un jeu de données en se basant sur les valeurs distinctes d’une ou plusieurs colonnes.
- Extraire les observations uniques de mon data.frame:
ma_table %>% distinct()
- Extraire les observations uniques d’une ou plusieurs colonne :
ma_table %>% distinct(colonne1, colonne2) Ne renvoie que les colonnes sélectionnées.
A VOUS DE CODER
A partir du jeu de données “penguins_raw”, créer un nouveau jeu de données répondant aux consignes suivantes :
- Sélectionner les colonnes : “Species”, “Date Egg”, “Body Mass (g)”
- Renommer les colonnes pour enlever les caractères spéciaux, les espaces et les majuscules
- Recoder la colonne “species” pour extraire les espèces (adelie, gentoo et chinstrap)
- Créer une nouvelle colonne “mois” qui correspond au mois (écrit en lettre) de la colonne “date_egg” (utilisation des fonctions
case_when()etmonth()) - Ne récupérer que les observations de novembre
- Par espèce, extraire les observations des 10 pingouins les plus lourds (utilisation de la fonction
slice_max()) - Faire une boite à moustache pour visualiser la dispersion des poids lourds pour chaque espèce
Les jointures
Il existe tout un panel de fonctions. Par exemple :

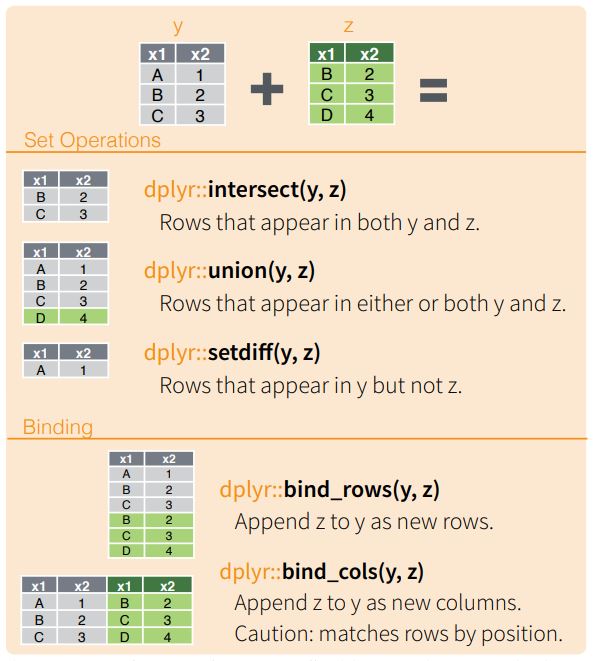
Les jointures
| name | rotation_period | orbital_period | diameter | climate | gravity | terrain | surface_water | population |
|---|---|---|---|---|---|---|---|---|
| Tatooine | 23 | 304 | 10465 | arid | 1 standard | desert | 1 | 2e+05 |
| Alderaan | 24 | 364 | 12500 | temperate | 1 standard | grasslands, mountains | 40 | 2e+09 |
| name | height | mass | homeworld |
|---|---|---|---|
| Luke Skywalker | 172 | 77 | Tatooine |
| C-3PO | 167 | 75 | Tatooine |
Les jointures
| name | height | mass | homeworld | population |
|---|---|---|---|---|
| Luke Skywalker | 172 | 77 | Tatooine | 2.0e+05 |
| C-3PO | 167 | 75 | Tatooine | 2.0e+05 |
| R2-D2 | 96 | 32 | Naboo | 4.5e+09 |
| Darth Vader | 202 | 136 | Tatooine | 2.0e+05 |
| Leia Organa | 150 | 49 | Alderaan | 2.0e+09 |
| Owen Lars | 178 | 120 | Tatooine | 2.0e+05 |
| Beru Whitesun lars | 165 | 75 | Tatooine | 2.0e+05 |
| R5-D4 | 97 | 32 | Tatooine | 2.0e+05 |
PIVOT_LONGER
Permet de regrouper (ou rassembler) plusieurs colonnes en une seule colonne, en utilisant les noms des colonnes comme valeurs de la nouvelle colonne “key” et les valeurs correspondantes comme valeurs de la nouvelle colonne “value”.
ma_table %>% pivot_longer(cols = c(colonne_1, colonne_2, colonne_3), names_to = nom_colonne_clé, values_to = nom_colonne_valeur)
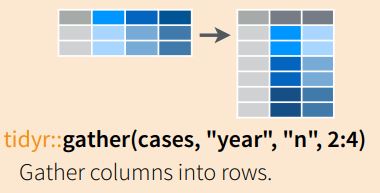
PIVOT_LONGER
| name | indice | valeur |
|---|---|---|
| Ackbar | height | 180 |
| Ackbar | mass | 83 |
| Adi Gallia | height | 184 |
| Adi Gallia | mass | 50 |
| Anakin Skywalker | height | 188 |
| Anakin Skywalker | mass | 84 |
| Arvel Crynyd | height | NA |
| Arvel Crynyd | mass | NA |
PIVOT_WIDER
Permet d’étaler une colonne de données en plusieurs colonnes, en utilisant les valeurs de cette colonne comme noms de colonnes.
ma_table %>% pivot_wider(names_from = colonne_clé, values_from = colonne_valeur)
colonne_clé: le nom de la colonne existante qui contient les valeurs qui deviendront les noms des nouvelles colonnes.
colonne_valeur: le nom de la colonne existante qui contient les valeurs qui seront distribuées (spread) dans les nouvelles colonnes.

PIVOT_WIDER
| homeworld | female | male | none | hermaphroditic |
|---|---|---|---|---|
| Naboo | 3 | 7 | 1 | NA |
| Tatooine | 2 | 6 | 2 | NA |
| Alderaan | 1 | 2 | NA | NA |
| Corellia | NA | 2 | NA | NA |
| Kamino | 1 | 2 | NA | NA |
| Kashyyyk | NA | 2 | NA | NA |
| Aleen Minor | NA | 1 | NA | NA |
| Bespin | NA | 1 | NA | NA |
A VOUS DE CODER
A partir du jeu de données “penguins” :
- Créer un jeu de données qui synthétise pour chaque espèce et chaque sexe, l’écart-type de la longueur du bec. Enlever l’observation qui a pour espece = adelie et sex= female
- Créer un autre jeu de données qui synthétise pour chaque espèce et chaque sexe, le poids médian. Enlever l’observation qui a pour espece = gentoo et sex= male
- Faire un left_join des deux tables créées. Quelle observation est manquante ?
- Faire un right_join des deux tables créées. Quelle observation est manquante ?
- Faire un inner_join des deux tables créées. Quelle(s) observation(s) est/sont manquante(s) ?
- Regrouper les colonnes décrivant l’écart-type du bec et le poids médian dans une seule et même colonne
Resources
Tutoriels - Data Science avec R - R Cookbook - Quick-R
Galleries - R Graphics Gallery
Livres - The R Book - Statistical Rethinking
Cours - Lectures Statistical Rethinking - eLearning INRAE
Débuggage - Stack Overflow - R-help
